

This REU Site project will engage motivated students in the rapidly growing research area of disinformation detection and analytics. With its focus on identifying disinformation, this program will broaden the views of the students, providing them with a holistic and in-depth understanding of disinformation and its viral spread across the Web. They will leverage knowledge and skills learned to discern and debunk disinformation, which could aid their families, friends, and social media contacts and eventually help prevent disinformation from spreading. Their knowledge and skills will not only prepare students for disinformation-related jobs in research or industry, it will encourage them to pursue graduate study and research in general. This program will also contribute to the development of a diverse, globally competitive workforce by providing research and education opportunities to an economically diverse group of students, including female, underrepresented minorities, first-generation college students, and those from undergraduate institutions who may not have previous exposure to research or graduate school.
Students participating in the REU Site project will learn: (1) The concept of disinformation, its types, examples, and active research topics, (2) Mainstream computational methods to detect disinformation on social media, including how to access, clean, preprocess, and visualize data and how to build analytical and predictive models using open source programming tools, (3) Important metrics to evaluate research results, compare baseline models, and produce preliminary results for publication quality research products, and (4) Essential research skills including brainstorming discussion, programming experiments, forensics, trial-and-error, technical writing, and research presentation. Students will conduct hands-on research on topics of their own choosing that fit within faculty members' existing broad disinformation research programs. The goal of this REU Site is to engage participating students in real-world projects studying disinformation from the perspectives of data analytics, information retrieval, applied machine learning, web archiving, and social computing. The participants will learn essential knowledge and skills to support future careers, whether research or application oriented. Co-funding for this project is being provided by the Secure and Trustworthy Cyberspace (SaTC) program and the Cybercorps/Scholarship for Service (SFS) program in recognition of the alignment of this project with the goals of these two programs.
About
-
$6,000 stipend
-
$600 travel subsidy
-
Housing & meals provided (On-campus)
-
Field trips and guest lectures
-
Be a rising sophomore, junior, or senior currently enrolled in an undergraduate program. All academic majors and disciplines will be considered, but preference will be given to those in Psychology, Engineering, or related fields
-
Be a US citizen or permanent resident
-
Preferred GPA 3.00 or higher
-
Must submit a resume/CV, cover letter (personal statement), transcripts, writing sample, and at least 1 letter of recommendation along with application
-
Research full time with faculty mentor for 10 weeks
-
Attend weekly lectures/workshops and field trips
-
Create a poster presentation at the conclusion of the summer
-
$6,000 stipend
-
$600 travel subsidy
-
Housing & meals provided (On-campus)
-
Field trips and guest lectures
-
Be a rising sophomore, junior, or senior currently enrolled in an undergraduate program. All academic majors and disciplines will be considered, but preference will be given to those in Psychology, Engineering, or related fields
-
Be a US citizen or permanent resident
-
Preferred GPA 3.00 or higher
-
Must submit a resume/CV, cover letter (personal statement), transcripts, writing sample, and at least 1 letter of recommendation along with application
-
Research full time with faculty mentor for 10 weeks
-
Attend weekly lectures/workshops and field trips
-
Create a poster presentation at the conclusion of the summer
Projects
Mentor: Dr. Nelson
Screen captures (screencaps) of social media are a popular way to share quotes and attributions in social media. There are a number of reasons why screencaps might be used: to highlight someone's post without driving up their engagement numbers (impressions, retweets, clicks, etc.), to facilitate cross-platform sharing , or to share a post that is at risk of being edited or deleted. Unfortunately, sharing only an image of a post, especially from another platform, is an opportunity for disinformation. For example, Figure 1 shows two Facebook posts with screencaps: one is of a real Instagram post showing two potential hurricanes headed toward New Orleans, and the other is of a fake tweet (complete with one million retweets) about how much I love screencaps (I really don't).
This fits in an emerging area we are calling Web Archiving Forensics, which includes establishing authenticity in a multi-archive environment (spoiler: Blockchain does not help). In particular we use web archives and social media to establish the probability of what public figures actually said (e.g., Joy Ann Reid's blog), did not say (e.g., a Utah Jazz fan), or said and then deleted (e.g., methods for surfacing deleted tweets and web pages deleted but not yet archived)
The research goals for the students would include creating, evaluating, and sharing (e.g., via GitHub):
- a gold standard data set of authentic and inauthentic examples of social media screencaps,
- methods and tools for detecting and extracting structural metadata, and
- methods and tools for providing a probability the screencap is either real or fake.
Student Learning Outcomes:
Students will learn: social media APIs; web crawling and page scraping; web archive APIs, including Memento and CDX; and image processing, including OCRing and segmentation.
Mentor: Dr. Ashok
To interact with web content, blind users rely on screen readers, a special-purpose assistive technology that narrates the contents of a webpage and also enables content navigation via keyboard shortcuts. Therefore, unlike sighted users, blind users cannot rely on visual cues (e.g., color, fake advertisement image, fake video, etc.) to identify deceptive online content such as advertisements, malicious links, product demos, etc. As a consequence, blind users are more susceptible to online scams and attacks, as they are more likely to navigate to untrustworthy websites, and download and install malicious software. Currently, no accessibility solution exists that can detect and alert blind users about deceptive content in webpages.
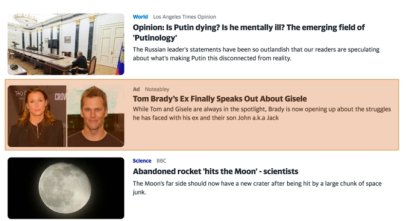
In this project, students will develop novel interactive systems that leverage artificial intelligence (AI) based solutions to assist blind users in identifying and circumventing deceptive content. Towards this, the students will first conduct contextual inquiries to understand in-depth the susceptibility of blind users to different kinds of deceptive content, and the impact of the absence of alternatives to visual cues for interacting with such content. Then, the students will build machine learning models to automatically identify deceptive content. Specifically, the students will extend prior works on semantic webpage analysis, to also include automatic deceptive segment extraction. Lastly, the students will design, develop and evaluate usable non-visual user interfaces that will leverage these algorithms to assist blind screen-reader users in avoiding deceptive content.
Student Learning Outcomes:
The students will learn the importance of web accessibility, and how modern artificial intelligence techniques can be leveraged to address the accessibility needs of people with visual disabilities, specifically regarding online security. They will be trained on how to build annotated datasets of webpages, experiment with supervised machine learning models including deep neural networks, design and develop non-visual usable interfaces, design and conduct user studies for evaluation, and lastly, analyze and interpret user data.
Mentor: Dr. Frydenlund
Memes are cultural artifacts that spread and evolve from person to person. These can represent any number of things from jingles and fashion to hashtags and images. Political memes are sometimes regarded as a form of protest art. These images with simple text or hashtags convey disdain for different political viewpoints and can go viral on multiple social media platforms, but also contribute to disinformation. These digital, fleeting cultural artifacts not only contribute to modern political discourse, they shape individual and collective action, from protest movements to violence.
As the world faces an unprecedented surge in refugees and increasing polarized political climates, political memes about refugees and refugee policies have real implications for human rights. Little research has been done to look at how viral memes, both pro- and anti-refugee, impact refugee response and policies. Our prior work using ftvitter and mobile phone data suggests that online sentiment correlates with real-world violence against Syrian refugees in Turkey.
Students will develop a measure of influence and political leaning of refugee-related memes, the definition of which they must creatively determine based on their understanding of the project.
Student Learning Outcomes:
Students will learn to mine social media data, conduct sentiment analysis, and tie those computational skillsets with qualitative analyses of news articles, political speeches, and policy documents to try to understand how memes influence real-world politics. Students will identify pro- and anti- refugee memes tied to the same country, political debate, and/or incident. They will investigate, using a variety of digital and qualitative methods, to determine veracity, influence, political leaning, and real-world implications for political action/protest connected to the meme.
Mentor: Dr. Perrotti
The research-to-practice pipeline is crucial to advance theory, inform treatment protocols, and identify public health solutions. The internet, digital technology, and social media have significantly changed how peer-reviewed empirical data is shared, publicized, and utilized. Changes in how health and science information is communicated to the public has had both negative and positive outcomes.

The immediacy and availability of important scientific results can empower and engage specific patient populations through support and improved patient-physician relationships. However, social media platforms have introduced far-reaching dissemination and rapid influence of fake news to a degree higher than verifiable news creating unique challenges for helping professions. These challenges include clarifying false rumors about disease outbreaks and vaccine safety responding to unfounded skepticism about medical treatments and addressing patient inaccuracies regarding recommended management protocols. There is a critical need to examine social media platforms impact on scientific practice for the helping professions as it relates to frequency of occurrence, mode and prevalence of exposure, role of confirmation bias, and impact on individual outcomes.
Student Learning Outcomes:
Students will develop measures of transmission of medical disinformation on digital platforms and use computerized analytics to quantify the impact on college student's decision making. Students will identify messaging and transmission of health-related information (i.e., regarding medical, mental, or physical health) across a variety of social media platforms. Students will learn to evaluate and define interprofessional themes and terminology, apply data extraction methods across a variety of social platforms, and analyze quantitative and qualitative data for themes and significant outcomes.
Mentor: Dr. Jayarathna
With the ever increasing spread of disinformation on online platforms, there is a critical need to investigate the factors of human judgment during the interaction with scientific articles (truthfulness of articles). For example, research has shown that eye tracking technology can identify a variety of aspects that can relate to the learning process (e.g. moments of confusion, boredom, delight), as well as aspects about the cognition. In our prior work, we focused on gaining insight from the eye movements of novice readers while reading a scientific paper using multiple eye-tracking measures. We expanded this work in to study of eye-tracking measures during a reading task with the options for zooming and panning of the reading material with eye tracking techniques.
The main goal of this project is to analyze unconstrained reading patterns of digital documents using eye movement fixations and dwell time on various sections of a digital document. We will focus on limiting false-positive key point matching between the on-screen content and a scientific paper content. This particularly useful when assessing the unconstrained reading patterns with less distinctive features such as images, charts, and tables.
The goal of this research project is to use eye tracking techniques to record eye movement activities during reading tasks, study reading patterns of participants, investigate feature set to identify objective measurements to assess engagement with fake scientific articles.
Student Learning Outcomes:
Students will develop experimental designs using eye tracking techniques to investigate how individuals assess the credibility of information, how they evaluate whether an information source is trustworthy, and how they identify and respond to disinformation. Students will learn how to process raw eye gaze data streamed from the eye tracker to our eye movements analytic pipeline to generate the traditional positional gaze and complex pupillometry measurements.
Mentor: Dr. Wu
Nowadays, people are using laptops or mobile devices for many daily activities. Reading news via Facebook, Instagram, Twitters occupies the bulk of the screen time. Statistics indicate that 62% of U.S. adults were exposed to news on social media in 2016 as opposed to only 49% in 2012. However, public digital media can often mix factual information with fake scientific news, which is typically difficult to pinpoint, especially for non-professionals. One example is the article posted on NatureNews.com titled "Don't Look Now, But Arctic Sea Ice Mass Has Grown Almost 40% Since 2012" (see the figure below), which attempts to cast doubt on the scientific veracity of global warming. These scientific news articles create illusions, misconceptions and ultimately influence the public opinion with serious consequences even at a much broader, societal scale. Many peer-reviewed papers have been published, providing evidence to refute the opinions and justifications in the fake news above. Most fact-checking services such as snopes.com, trace provenance through laborious, fully manual web browsing, and cross-verification procedures. The existing solutions aimed at automatically verifying the credibility of news articles are still unsatisfactory.

In this project, students will investigate computational methods to automatically find evidence of scientific disinformation from a large collection of scientific publications. The goal is to find an effective model to recommend the most relevant scientific articles that helps readers to better assess the credibility of scientific news, and locate the most relevant claims. The work will augment an existing method we proposed by investigating novel machine learning and information retrieval models, aiming at improving the accuracy and narrowing down the relevancy granularity level from documents to paragraphs. Students will have opportunities to perform a full stack project from data compilation, model training, evaluation, writing reports, and presentation.
Student Learning Outcomes:
Students will learn how to convert a real-world problem to a fundamental machine learning problem. They will be trained on how to collect and preprocess scientific news data from another data release and apply state-of-the-art models and neural search engines to facilitate fake scientific news detection.
Mentor: Dr. Wu
Nowadays, people are using laptops or mobile devices for many daily activities. Reading news via Facebook, Instagram, Twitters occupies the bulk of the screen time. Statistics indicate that 62% of U.S. adults were exposed to news on social media in 2016 as opposed to only 49% in 2012. However, public digital media can often mix factual information with fake scientific news, which is typically difficult to pinpoint, especially for non-professionals. One example is the article posted on NatureNews.com titled "Don't Look Now, But Arctic Sea Ice Mass Has Grown Almost 40% Since 2012" (see the figure below), which attempts to cast doubt on the scientific veracity of global warming. These scientific news articles create illusions, misconceptions and ultimately influence the public opinion with serious consequences even at a much broader, societal scale. Many peer-reviewed papers have been published, providing evidence to refute the opinions and justifications in the fake news above. Most fact-checking services such as snopes.com, trace provenance through laborious, fully manual web browsing, and cross-verification procedures. The existing solutions aimed at automatically verifying the credibility of news articles are still unsatisfactory.
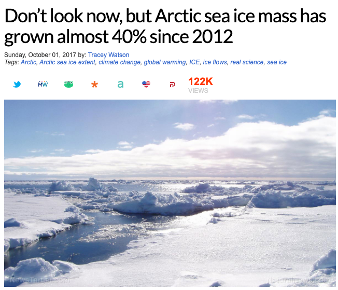
Image credit: Center for Countering Digital Hate (CCDH), "Malgorithm: How Instagram's algorithm publishes misinformation and hate to millions during a pandemic", March 2021, https://www.counterhate.com/malgorithm
Students will investigate disinformation campaigns on Instagram and develop methods for accessing and analyzing historical metadata of Instagram accounts and posts using web archives. Providing this metadata to users will help them become more discerning consumers of information shared on social media. We have a current graduate student who has begun an investigation of how well Instagram pages are covered in public web archives. Students on this project would be extending this work, focusing on accounts and posts disseminating disinformation.
The objective of this project is to develop methods for gathering and providing important metadata about potential sources of disinformation to Instagram users. The techniques developed can also be applied to other social media platforms to provide support for other projects at this REU Site.
Student Learning Outcomes:
Students will gain experience with both technological and sociological aspects of social media, including how Instagram pages are delivered to browsers, how to mine web archives for historical metadata, and the techniques of those who spread disinformation. Students will gain immediate practical knowledge in Python, R, how to use Web APIs, and how to develop effective visualizations from their collected data.
Mentor: Dr. Poursardar
Online platforms lay an important role in our daily life. Before you buy a product on Amazon, you look at the rating of that product, read the reviews and pay attention to what people said about that product. When you want to go out for a dinner, you read the reviews n that restaurant before you make the decision which restaurant you are willing to choose. When you want to watch a movie, you read the reviews on that movie. When you want to choose your new doctor, you read the reviews on web about her/him. When you want to download a new application on your phone, you look at the ratings for that specific application. As you see in these examples, user reviews are very important as they impact our decisions. Fraudulent or mis-informed reviews can degrade the trust in online platforms.
Crowdsourcing websites use Internet to hire and involve individuals remotely located to perform on-demand tasks. Businesses usually post jobs known as Human Intelligence Tasks (HITs), such as a survey, identifying specific content in an image or video, writing product descriptions, answering questions, writing a (good) review for a product to promote it, like/vote for a video on YouTube. Workers known as crowdworkers browse the existing jobs, complete them and get paid for a rate set by the employer. The nature of the job helps crowdworkers to work remotely and get paid. The last two examples of crowdsourced jobs - provide a review for a product or service and vote for a video- could be used for the purpose of creating disinformation and/or fraudulent reviews in online platforms.
For example, the following figure shows two examples of fraudulent job descriptions on Rapid Workers.
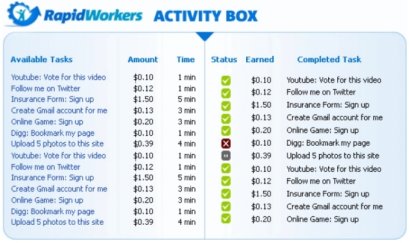
Detecting fraudulent reviews and review writers directed from crowdsourced results is vital and should be considered as a way to protect online communities.
Student Learning Outcomes:
- In this project, students will learn how to extract and analyze data and text from online platforms like Amazon, Rapid Workers, and/or Amazon Mechanical Turk.
- In this project, students will learn: web crawling, page scraping and extract text from online platforms like Amazon, Rapid Workers, and/or Amazon Mechanical Turk; analyze extracted data; identify user behavior patterns.

Research Mentors







FAQ's
Applicants will be evaluated on academics, research/work experience, and interest in Computer Science as a field of study or possible career. There are several steps to applying:
- Read through the available projects (located in the "projects" tab) and identify which projects you would be most interested in working on.
- Complete the Application form from ETAP application system.
- Gather your supporting documents. You will need to upload all the following documents in order to be considered for the program:
- A resume or CV
- A cover letter (up to one page) detailing your interest in computer sciences, relevant research experience and career or academic goals
- An unofficial transcript of all colleges you've attended (official transcripts will be required on acceptance to the program)
- One letter of recommendation
- A writing sample (must have been written independently, not part of a group project).
Yes! Preference will be given to applicants with a background in computer science, data science, information science or other STEM fields, but we encourage all majors with a strong interest in Computer sciences to apply (including those who have not yet declared a major).
Yes! Students with a strong interest in computer science from all backgrounds are encouraged to apply. In addition, we strongly encourage applicants from groups currently underrepresented in STEM fields (women, minorities, and persons with disabilities).
The REU program is 10 weeks long. It is a full-time program. You will be working alongside a faculty mentor to complete a project. Once a week, there will be an event focused on your professional or academic development. This might include guest lecturers from the computer science field, workshops on how to apply to graduate programs, or field trips to relevant research centers.
Old Dominion University (ODU) is located in Norfolk, VA. ODU is the largest university in the area, with over 100 academic programs and 24,000 students. The campus boasts a 355 acre campus with plenty of dining options and even its own art museum! Norfolk, VA is a vibrant city with several cultural districts and just a few minutes away from the beach! If accepted, you will have the opportunity to live at ODU. When not conducting research, you will be able to take full advantage of what ODU and the greater Norfolk area has to offer.